
AI入门
前言
笔者在阅读全球掀起DeepSeek复现狂潮,一文汇总! 的时候,对其中的众多概念表示无法理解。转念一想,不妨做一篇博客,收录核心的有关AI的词汇。
人工智能(AI)
人工智能是让机器模拟人类智能行为的科学与技术。它涵盖多个领域,如机器学习、深度学习、自然语言处理(NLP)、计算机视觉等。
生成式AI
生成式AI是AI的一个分支,专注于生成新内容(如文本、图像、音频、视频)。它的核心是学习数据的分布,并从中生成类似的新数据。
例子:ChatGPT(生成文本)、DALL·E(生成图像)、Stable Diffusion(生成图像)。
预训练(Pre-training)
它通过在大规模数据集上训练模型,使其学习通用的语言或视觉特征,然后再针对特定任务进行微调。
微调(Fine-tuning)
微调是在预训练模型的基础上,用特定任务的数据进一步训练模型,使其适应具体任务。
蒸馏(Distillation)
蒸馏是一种模型压缩技术,目的是将大型模型(教师模型)的知识转移到小型模型(学生模型)中,使小模型在保持高性能的同时减少计算资源需求。
- 过程:
- 训练一个大型、高性能的教师模型。
- 让教师模型生成“软标签”(概率分布),而不是硬标签(具体类别)。
- 训练学生模型模仿教师模型的输出。
- 优点:小模型更轻量、更快,适合部署在手机、嵌入式设备等资源受限的场景。
- 例子:DistilBERT 是 BERT 的蒸馏版本,参数更少但性能接近。
模型剪枝(Model Pruning)
是一种模型压缩技术,旨在通过移除神经网络中不重要的部分(如权重、神经元或层)来减少模型的大小和计算量,同时尽量保持模型的性能。剪枝可以帮助模型在资源受限的设备(如手机、嵌入式设备)上高效运行。
后训练
基于预训练基础,指在模型完成训练后,对其进行进一步优化或处理的过程。这些优化通常是为了提高模型的效率、性能或适应性,而不需要重新训练整个模型。后训练技术在现代深度学习中非常重要,尤其是在资源受限的场景中(如移动设备、嵌入式系统)。
Transformer
一种深度学习模型架构,广泛应用于生成式AI(如 GPT、BERT)。它的核心是自注意力机制,可以捕捉长距离依赖关系。
Prompt(提示词)
用户输入的指令或问题,用于引导生成式AI生成特定内容。
Token(词元)
生成式AI处理文本的基本单位,可以是单词、子词或字符。
损失函数(Loss Function)
衡量模型预测与真实值差异的函数,用于指导模型优化。
过拟合(Overfitting)
模型在训练数据上表现很好,但在新数据上表现差,通常是因为模型过于复杂或训练数据不足。
参数
指在机器学习模型(尤其是深度学习模型)中可训练参数的个数
- 模型容量:参数越多,模型的表达能力越强,能够学习更复杂的模式和关系。
- 计算资源:参数越多,模型需要的计算资源(如内存、算力)也越多。
- 训练数据需求:参数越多的模型通常需要更多的训练数据,以避免过拟合。
总之:参数数量类似于大脑中的神经元连接数。参数越多,模型“思考”能力越强,但也需要更多“能量”(计算资源);参数越多,模型性能可能越好,但训练和推理成本也越高。因此,实际应用中需要在性能和效率之间找到平衡。
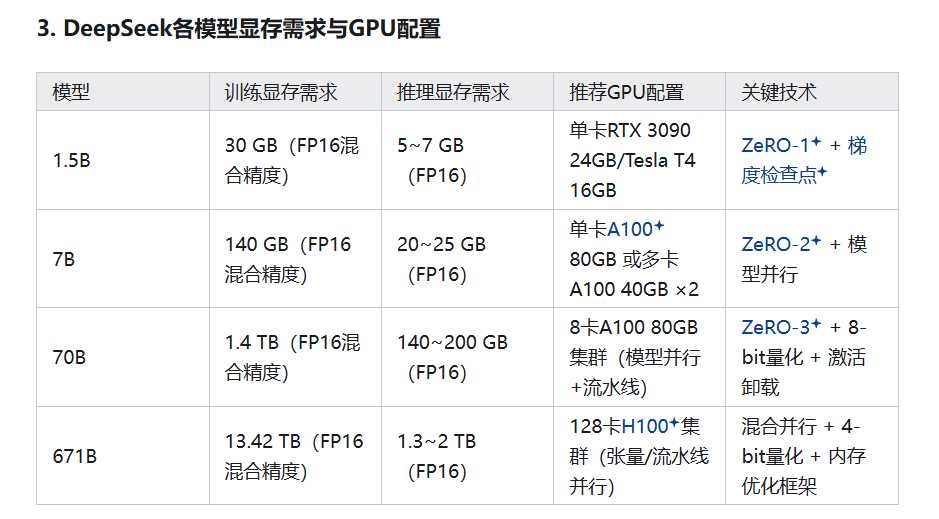
B = Billion(十亿参数):表示模型的参数量级,直接影响计算复杂度和显存占用。
DeepSeek 1.5B:15亿参数(小型模型,适合轻量级任务)
DeepSeek 7B:70亿参数(主流规模,平衡性能与资源)
DeepSeek 70B:700亿参数(高性能需求场景)
DeepSeek 671B:6710亿参数(超大规模,对标PaLM/GPT-4)
RAG(检索增强生成)
是检索(Retrieval)、增强(Augmented)、生成(Generation)三个词的首字母组合。以DeepSeek为例,当你下达了“网络搜索”的命令,DS会去网络上检索有关信息(R),然后将答案整合(A),通过LLM生成(G)一段通顺的文本。
 wechat
wechat alipay
alipay
