二叉树的存储结构 顺序存储 即用数组来存储,从上到下,从左到右,将编号为i的结点存在数组下标为i-1的位置上。
链式存储 1 2 3 4 typedef struct BiTNode { element data; struct BiTNode *left , *right ; }BiTNode,*BiTree;
二叉树的遍历与线索二叉树 先序遍历的递归操作 1 2 3 4 5 6 7 void PreOrder (BiTree T) { if (T != NULL ){ visit(T); PreOrder(T->lchild); PreOrder(T->rchlid); } }
中序遍历的递归操作 1 2 3 4 5 6 7 void InOrder (BiTree T) { if (T != NULL ){ InOrder(T->lchild); visit(T); InOrder(T->rchild); } }
后序遍历的递归操作 1 2 3 4 5 6 7 8 void PostOrder (BiTree T) { if (T != NULL ){ PostOrder(T->lchild); PostOrder(T->rchild); visit(T); } }
总结 在递归遍历中,递归工作栈的深度为树的深度,高度为n的二叉树的遍历时间复杂度为O(n)
先序遍历的非递归操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 void PreOrder (BiTree T) { InitStack(&S); BiTree p = T; while (p || !IsEmpty(S)){ if (p){ visit(p); Push(S,p); p = p ->lchild; }else { Pop(S,p); p = p ->rchild; } } }
中序遍历的非递归操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void InOrder (BiTree T) { InitStack(&S); BiTree p = T; while (p || !IsEmpty(S)){ if (p){ Push(S,p); p = p ->lchild; } else { Pop(S,p); visit(p); p = p ->rchild; } } }
后序遍历的非递归操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void PostOrder (BiTree T) { BiTNode *p = T; BiTNode *r = NULL ; InitStack(*S); if (p != NULL && !IsEmpty(s)){ if (p){ Push(S,p); p = p->lchild; } else { GetTop(S,p); if (p->rchild != NULL && p->rchild != r){ p = p->rchild; }else { Pop(S,p); visit(p); r=p; p=NULL ; } } }
完全二叉树12345会触发p->rchild != r
层次遍历 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void LevelOrder (BiTree T) { InitQueue(Q); BiTree p; EnQueue(Q,T); while (!IsEmpty(Q)){ DeQueue(Q,p); visit(p); if (p->lchild != NULL ){ EnQueue(Q,p->lchild); } if (p->rchild != NULL ){ EnQueue(Q,p->rchild); } } }
由遍历序列确定二叉树
由先序序列和中序序列确定二叉树
由中序序列和后序序列确定二叉树
由中序序列和层次序列确定二叉树
由先序序列或者后序序列 与层次序列 不能确定二叉树
线索二叉树的存储结构 1 2 3 4 5 typedef struct ThreadNode { ElementType data; struct ThreadNode *lchild ,*rchild ; int ltag,rtag; }ThreadNode,*ThreadTree
构造中序线索二叉树 实质上是中序二叉树线索化:即遍历中序二叉树,将其“升级”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void InThread (ThreadNode *p,ThreadNode *pre) { if (p != NULL ){ InThread(&(p->lchild),&pre); if (p->lchild == NULL ){ p->lchild = pre; p->ltag= 1 ; } if (pre != NULL && pre->rchlid == NULL ){ pre->rchlid = p; pre->rtag = 1 ; } pre = p; InTree(&(p->rchild),&pre); } }
1 2 3 4 5 6 7 8 9 10 11 12 void CreateInThread (ThreadNode *T) { ThreadTree pre = NULL ; if (T != NULL ){ InThread(&T,&pre); pre->rchild = NULL ; pre->rtag = 1 ; } }
带头结点的中序线索二叉树 头结点lchild指向根节点;rchild指向遍历序列最后一个结点。
中序线索二叉树的遍历
求结点下一个结点
1 2 3 4 5 6 ThreadTree *FirstNode (ThreadNode *p) { while (p->ltag != 0 ){ p = p->lchild } return p; }
求结点p的后继
1 2 3 4 5 6 7 ThreadTree *NextNode (ThreadNode *p) { if (p->rtag == 0 ){ return FirstNode(&p); }else { return p->rchild; } }
中序遍历线索二叉树
1 2 3 4 5 void InOrder (ThreadNode *T) { for (ThreadNode *p=FirstNode(&T);p!=NULL ;p=NextNode(&p)){ visit(p); } }
算法 二叉树按照顺序存储方式 存储,求编号为i、j两个结点最近的公共祖先的值。 1 2 3 4 5 6 7 8 9 10 11 12 ElemType Comm_Ancestor (SqTree T,int i ,int j) { if (T[i] != '#' && T[j] != '#' ){ while (i != j){ if (i > j){ i = i / 2 ; }else { j = j / 2 ; } } return T[i]; } }
求用二叉链表 存储的二叉树的深度 1 2 3 4 5 6 7 8 9 10 11 12 13 int BtDepth (BiTree T) { if (T == NULL ){ return 0 ; } ldep = BtDepth(T->lchild); rdep = BtDepth(T->rchild); if (ldep > rdep){ return ldep + 1 ; }else { return rdep + 1 ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int BtDepth (BiTree T) { if (!T){ return 0 ; } int front = -1 ,last = -1 ; int last = 0 ,level = 0 ; BiTree Q[Max]; Q[++rear] = T; BiTree p = NULL ; while (front < rear){ p = Q[++front]; if (p->lchild){ Q[++rear] = p->lchild; } if (p->rchild){ Q[++rear] = p->rchild; } if (last == front){ level++; last = rear; } } }
二叉树按二叉链表 形式存储,怎么判断这棵二叉树是不是完全二叉树 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 bool IsCom (BiTree T) { if (T == NULL ){ return false ; } BiTree p = NULL ; InitQueue(&Q); EnQueue(&Q,T); while (!IsEmpty(Q)){ DeQueue(&Q,p); if (p){ EnQueue(&Q,p->lchild); EnQueue(&Q,p->rchild); }else { while (!IsEmpty(Q)){ DeQueue(&Q,p); if (p != NULL ){ return false ; } } } } return true ; }
二叉树按照二叉链表 形式存储,求有两个孩子结点的个数
不难想到使用层次遍历结合全局变量,但还可以递归
1 2 3 4 5 6 7 8 9 10 int Nodes (BiTree T) { if (T == NULL ){ return 0 ; } if (T->lchild != NULL && T->rchild != NULL ){ return Nodes(T->lchild)+Nodes(T->rchild)+1 ; }else { return Nodes(T->lchild)+Nodes(T->rchild); } }
建立递归模型是有助于分析的
二叉树B使用链式结构存储 ,交换它的左右结点 1 2 3 4 5 6 7 8 9 10 void swap (BiTree B) { if (B){ swap(B->lchild); swap(B->rchild); BiTree temp = NULL ; temp = B->lchild; B->lchild = B->rchild; B->rchild = temp ; } }
本题采用了后续遍历的思想。为什么是后续而不是前序、中序。因为后续最后遍历根节点,如果在遍历根节点前就已经完成了交换根节点左右子树的行为,再递归到根节点的右子树,实际上仍然是对根节点左子树的重复操作。
二叉树使用二叉链表形式存储 ,求先序遍历中第k个结点的值(1<=k<=n)
本题可以在先序遍历的非递归算法中做手脚。亦或采用递归算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int i = 1 ; ElemType find (BiTree T,int k) { if (T == NULL ){ return '#' ; } if (i == k){ return T->data; } i++; ch = find(T->lchild,k); if (ch != '#' ){ return ch; } ch = find(T->rchild,k); return ch; }
烧脑,
二叉树以二叉链表形式存储,删除每一个 值为x的结点
本题分两个函数:删除函数与遍历函数
1 2 3 4 5 6 7 void Delete (BiTree T) { if (T){ Delete(T->lchild); Delete(T->rchild); free (T); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 void Search (BiTree T,Element x) { BiTree Q[]; if (T->data == x){ Delete(T); exit (0 ); } InitQueue(&Q); DeQueue(&Q,T); while (!IsEmpty(Q)){ if (T->lchild != NULL ){ if (T->lchild->data == x){ Delete(T->child); T->child = NULL ; exit (0 ); }else { EnQueue(&Q,T->lchild); } } if (T->rchild != NULL ){ if (T->rchild->data == x){ Delete(T->rchild); T->rchild = NULL ; exit (0 ); }else { EnQueue(&Q,T->rchild); } } } }
在二叉树中,打印值为x的结点的所有祖先(值为x的结点不多于1个)
祖先:从根节点A到结点K的唯一路径 上的所有除K以外的其他结点
变种:设p\q为二叉树上的结点,找到它们最近的公共祖先
对原栈与辅助栈匹配
二叉树采用二叉链表形式存储,求非空二叉树b的宽度(具有节点数最多的那一层结点的个数) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 typedef struct { BiTree data[Max]; int level[Max]; int front,rear; }Qu; int BTWidth (BiTree b) { BiTree p ; int k = 0 ; Qu.front = Qu.rear = -1 ; Qu.rear++; Qu.data[Qu.rear] = b; Qu.level[Qu.rear] = 1 ; while (Qu.rear > Qu.front){ Qu.front++; p = Qu.data[Qu.front]; k = Qu.level[Qu.front]; if (p->lchild != NULL ){ Qu.rear++; Qu.data[Qu.rear] = p->lchild; Qu.level[Qu.rear] = k+1 ; } if (p->rchild != NULL ){ Qu.rear++; Qu.data[Qu.rear] = p->rchild; Qu.level[Qu.rear] = k+1 ; } } int max = 0 ; int n = 0 ; int i = 0 ; k = 1 ; while (i <= Qu.rear){ n = 0 ; while (i<=Qu.rear && Qu.level[i] == k){ n++; i++; } k = Qu.level[i]; if (k>max){ max = n; } } return max; }
对一棵满二叉树,已知先序遍历字符串,求后序遍历字符串
采用递归的思想
1 2 3 4 5 6 7 8 9 void PreToPost (ElemType pre[],int l1,int h1,ElemType post[],int l2,int h2) { int half = 0 ; if (h1>l1){ post[h2] = pre[l1]; half=(h1-l1)/2 ; PreToPost(pre,l1+1 ,l1+half,post,l2,l2+half-1 ); PreToPost(pre,l1+half+1 ,h1,post,l2+half,h2-1 ); } }
1 2 3 ElemType *pre = "ABCDEFG" ; ElemType post[Max]; PreToPost(pre,0 ,6 ,post,0 ,6 );
设计一个算法将二叉树的叶节点从左到右链接成为一个单链表,表头指针为head,二叉树使用二叉链表方式存储,叶节点的右孩子来存放单链表指针
遍历二叉树的叶子节点,前序、中序、后序都是先访问左节点,再访问右节点。这里采用中序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 LinkList head = NULL ,pre = NULL ; LinkList InOrder (BiTree bt) { if (bt){ InOrder(bt->lchild); if (bt->lchild == NULL && bt->rchild == NULL ){ if (pre == NULL ){ pre = bt; head =bt; }else { pre->rchlid = bt; pre = bt; } } InOrder(bt->rchild); pre->rchild = NULL ; } return head; }
时间复杂度O(n),栈复杂度O(n)。
判断两棵树是否相似。相似:T1、T2都为空或者都只有一个结点;或者它们的左子树是相似的;且他们的右子树是相似的
注意理解递归调用的返回值的去向,x调用y,y返回值返回给x
1 2 3 4 5 6 7 8 9 10 11 12 int similar (BiTree T1,BiTree T2) { int leftS = 0 ,rightS = 0 ; if (T1 == NULL && T2 == NULL ){ return 1 ; }else if (T1 == NULL || T2 == NULL ){ return 0 ; }else { leftS = similar(T1->lchild && T2->lchild); rightS = similar(T1->rchild && T2->rchild); return leftS && rightS; } }
森林用孩子兄弟表示法存储,求叶节点数
牢记递归的思想
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 typedef struct { Element data; CSNode *firstchild,*firstbro; }CSNode; int Count (CSNode T) { if (T == NULL ){ return 0 ; } if (T->firstchild == NULL ){ return Count(T->firstbro)+1 ; } else { return Count(T->firstchild) + Count(T->firstbro); } }
树用孩子兄弟表示法存储,求其高度
仍是采用递归的思想:将求树的高度 转化为求第一子女树的高度||兄弟子树高度 中的最大者。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int Height (CSTree T) { if (T == 0 ){ return 0 ; } int hc = 0 ,hb = 0 ; hc = Height(T->firstchild); hb = Height(T->firstbro); if (hc + 1 > hb){ return hc + 1 ; }else { return hb; } }
树与森林 树的存储结构
双亲表示法-顺序存储
1 2 3 4 5 6 7 8 9 10 11 #define max 100 typedef struct { Element data; int parent; }PTNode; typedef struct { struct PTNode node [max ]; int n; }PNode;
注意 :可用树的存储结构存二叉树,但不能反之。优点 :快速找到每个孩子的双亲结点,但找到孩子须遍历整个表。
孩子表示法-顺序存储
优点 :快速找到每个孩子的孩子结点,但找到双亲须遍历整个表。
孩子兄弟表示法-链式存储
1 2 3 4 typedef struct { Element date; CSTree firstchild,nextsibling; }CSNode,*CSTree;
优点 :方便实现树->二叉树的转换
树、森林与二叉树的转换
树->二叉树
森林->二叉树
二叉树->树
二叉树->森林
规则 :左孩子、右兄弟
树和森林的遍历
树的遍历
先根遍历(相当于其二叉树形态的先序遍历)
后根遍历(相当于其二叉树形态的中序遍历)
森林的遍历
先序遍历(相当于其二叉树形态的先序遍历)
中序遍历(相当于其二叉树形态的中序遍历)
总结
树与二叉树的应用 哈夫曼树与哈夫曼编码
几个概念
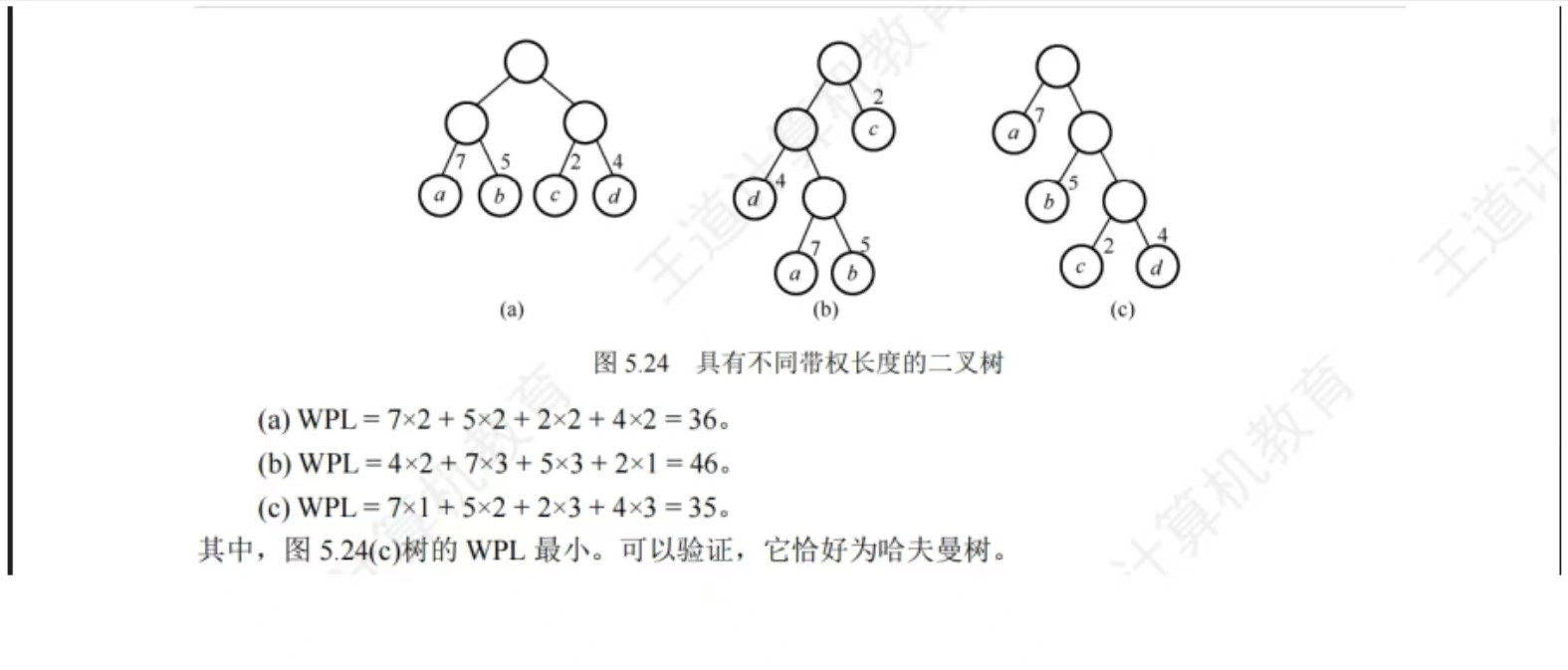
路径长度:路径上的分支数目
权:结点被赋予的数
结点的 带权路径长度(WPL):路径长度 * 权树的 带权路径长度(WPL):树中所有叶节点 的WPL之和
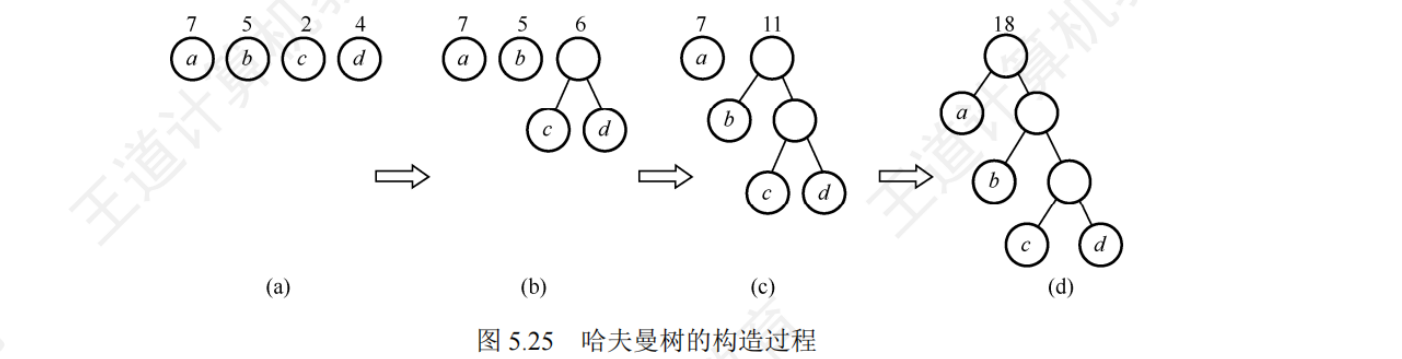
哈夫曼树的构造过程
哈夫曼树的性质
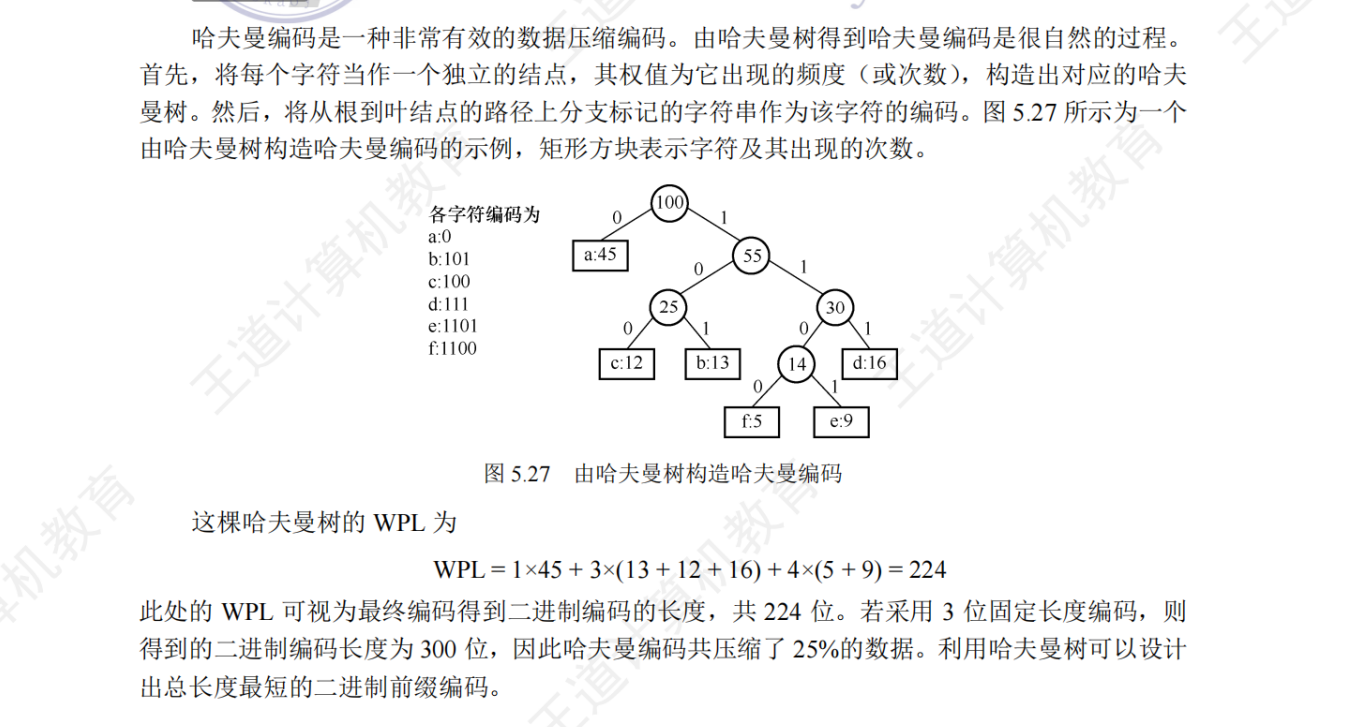
哈夫曼编码
固定长度编码:对每个字符使用相等 长度的二进制位
可变长度编码:对每个字符使用不等 长度的二进制位
前缀编码:没有一个编码是另一个编码的前缀(确定性)
与定长编码的比较
左右分支0\1没有明确规定等情况,会出现构造不唯一的哈夫曼树 的情况,虽然这些哈夫曼树不唯一,但是它们的WPL是相同的且为最优。
并查集 数组形式的集合,初始默认值为-1。当其值>=0时,代表的是父节点不是双亲 的数组下标;当其值<0时,其绝对值为孩子+1
基本实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #define SIZE 100 int UFSets[SIZE];void Init (int S[]) { for (int i = 0 ; i<SIZE ; i++){ S[i] = -1 ; } } int Find (int S[],int x) { while (S[x] >= 0 ){ x = S[x]; } return x; } void Union (int S[],int Root1,int Root2) { if (Root1 == Root2) return ; S[Root2] = Root1; }
Union操作的优化
极端情况下,n个元素构成的树的最大深度为n,则find的时间复杂度为O(n)
1 2 3 4 5 6 7 8 9 10 void Union (int S[],int Root1,int Root2) { if (Root1 == Root2) return ; if (S[Root1] < S[Root2]){ S[Root1]+=S[Root2]; S[Root2] = Root1; }else { S[Root2]+=S[Root1]; S[Root1] = Root2; } }
采用以上这种方法构造的集合树,深度不超过logn的向下取整+1
改进的find操作
即将欲找到的结点路径上的所有结点(包括它),都挂载到根上
1 2 3 4 5 6 7 8 9 10 11 int fine (int S[] , int x) { int root = x ; while (S[root] >= 0 ){ root = S[root]; } while (x != root){ int t = S[x]; S[x] = root; x = t ; } }


 wechat
wechat alipay
alipay


